

Zhipu AI официално отвори и пусна GLM-4.7-Flash, олекотен голям езиков модел, позициониран като наследник на GLM-4.5-Flash. Моделът вече е достъпен с безплатен API достъп и е предназначен за локално програмиране и приложения, базирани на агенти.

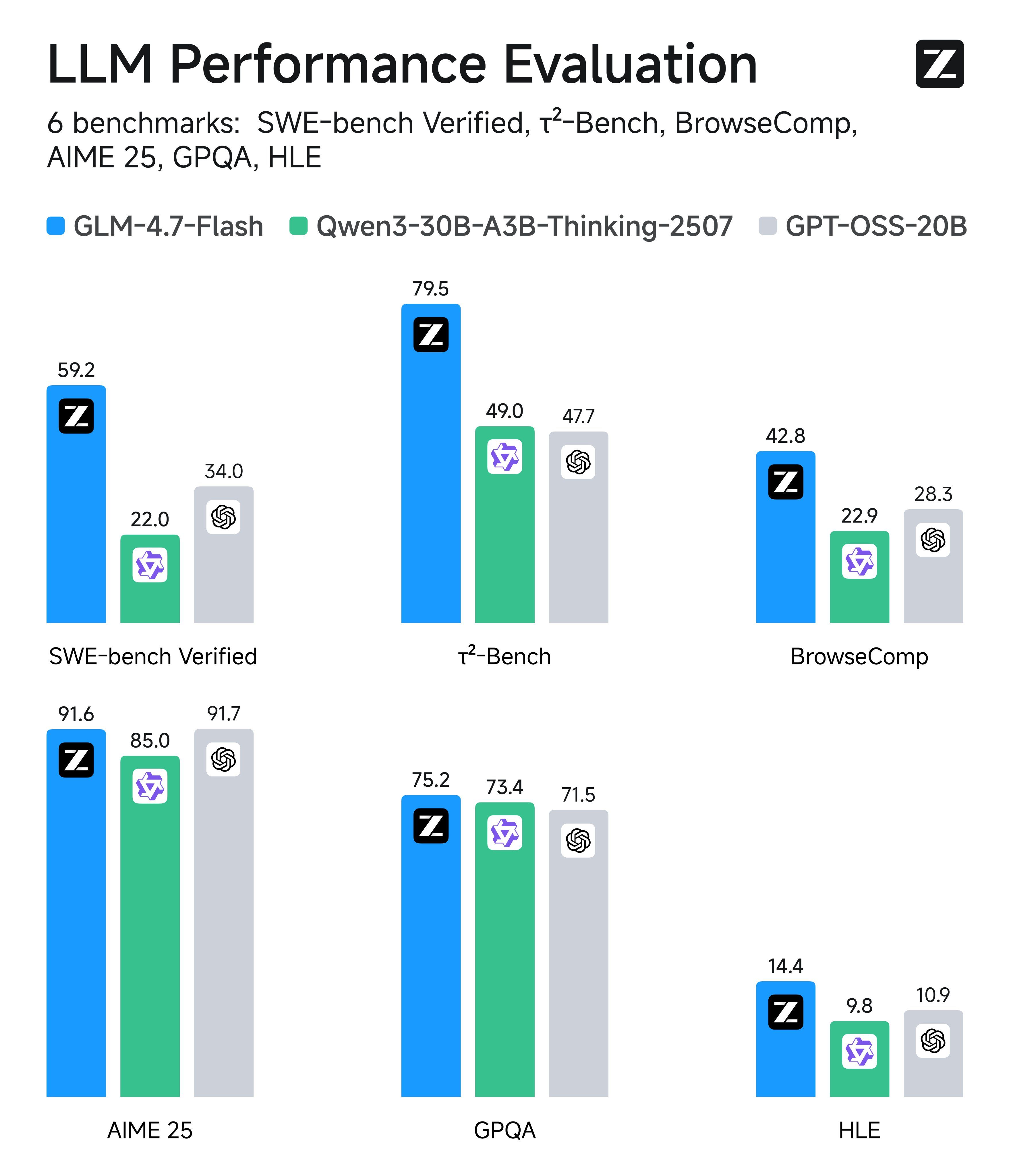
GLM-4.7-Flash приема архитектура Mixture-of-Experts (MoE) с общо 30 милиарда параметри, като същевременно активира само около 3 милиарда параметри по време на извод, което значително подобрява ефективността. На теста SWE-bench Verified за поправка на код в реалния свят, моделът постигна резултат от 59,2, демонстрирайки силни възможности за кодиране и разсъждение.
Забележителен технически акцент е първото използване от Zhipu на MLA (Multi-head Latent Attention) архитектура, подход, потвърден преди това от DeepSeek-v2, насочен към подобряване на ефективността на дългия контекст и ефективността на изводите. Моделът е оптимизиран за широк набор от задачи, включително творческо писане, превод и разсъждения в дълъг контекст.
Версията бързо спечели екосистемна поддръжка, като Hugging Face и vLLM осигуряват незабавна съвместимост. Налична е и официална поддръжка за Huawei Ascend NPU. При тестове за локално внедряване разработчиците съобщават за скорост на извеждане от 43 токена в секунда на лаптоп на Apple, оборудван с чип M5 и 32GB унифицирана памет. В търговската мрежа базовото API ниво е напълно безплатно (една едновременна заявка), докато високоскоростният GLM-4.7-FlashX е на конкурентна цена.
Източник: QbitAI
Source link
Like this:
Like Loading…
Нашия източник е Българо-Китайска Търговско-промишлена палaта
Related Posts

Новите подводни безпилотни системи на китайските военни са „разрушителни“, интелигентни: списание
Китайски военно списание е описал Народна освободителна армияПоследните подводни безпилотни…

Цените са намалени на повече от 200 модела автомобили в Китай тази година: експерт · TechNode
Към ноември общо 224 модела са намалили цените си от…

Американските военни убиха 3-ма при последния удар срещу лодка на „наркотерористи“.
Американските военни нанесоха нов смъртоносен удар срещу кораб, обвинен в…